|
I work as a senior applied scientist at Oracle since Nov, 2024. Before that, I obtained my CS Ph.D. degree at North Carolina State University, under the supervision of Dr. Tim Menzies in the RAISE Lab (Real-world Artifical Intelligence for Software Engineering). My research interest includes automated source code analysis and applying NLP approaches in static code analysis. Before coming to NC State, I obtained my bachelor degree of Information Management and Information System with GPA 90/100 in 2018. Email / Resume / Google Scholar / LinkedIn / GitHub |

|
|
My research interests focus on automated source code analysis through NLP and deep learning techniques, as well as software engineering and machine learning optimization. My projects include identifying static warnings using incrementally active learning and human-computer interaction to improve recall while minimizing costs by reducing the exploration of irrelevant static warning samples. Additionally, I work on feature extraction from programming languages and software engineering artifacts, utilizing embedding methods and NLP approaches. For more information about my research work, please visit my Google Scholar. |
|
|
 |
Develop generative models and features using advanced machine learning and NLP techniques (LLMs) for innovative healthcare projects. Conduct quantitative and qualitative analysis, including error analysis and ablation studies, to enhance model development and data quality. |
 |
Learn and extract features from linguistic description of change lists to Google internal codebase. Detect breakage and provide high-quality, cost-effective post-submission testing for Google3 (Regression Test Selection and Prioritization). |
 |
Developed techniques with recent advancements in natural language processing (Longformer, CodeBERT and learned token pruning algorithm) for detecting, mitigating and preventing modern threats in large-scale cloud environments. Addressed the quadratic memory requirement issue in self-attention mechanism by adapting the global and local attentions on PowerShell dataset. |
|
|
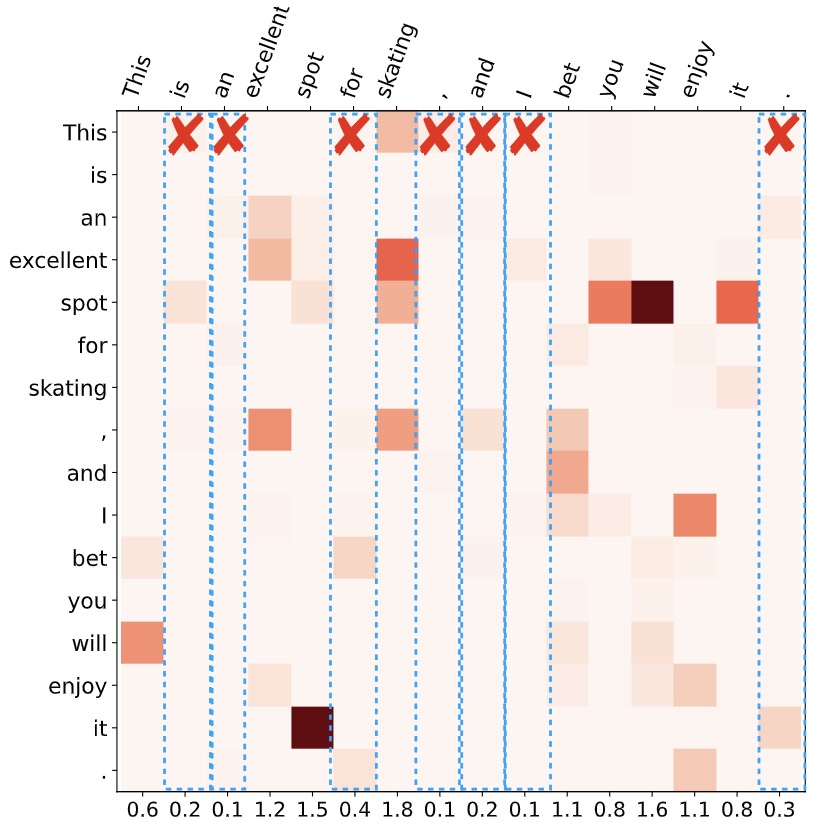 |
Xueqi Yang, Mariusz Jakubowski, Li Kang, Haojie Yu, Tim Menzies, Empirical Software Engineering As software projects rapidly evolve, software artifacts become more complex and defects behind get harder to identify. The emerging Transformer-based approaches, though achieving remarkable performance, struggle with long code sequences due to their self-attention mechanism, which scales quadratically with the sequence length. This paper introduces SparseCoder, an innovative approach incorporating sparse attention and learned token pruning (LTP) method (adapted from natural language processing) to address this limitation. Extensive experiments carried out on a large-scale dataset for vulnerability detection demonstrate the effectiveness and efficiency of SparseCoder, scaling from quadratically to linearly on long code sequence analysis in comparison to CodeBERT and RoBERTa. We further achieve 50% FLOPs reduction with a negligible performance drop of less than 1% comparing to Transformer leveraging sparse attention. Moverover, SparseCoder goes beyond making "black-box" decisions by elucidating the rationale behind those decisions. Code segments that contribute to the final decision can be highlighted with importance scores, offering an interpretable, transparent analysis tool for the software engineering landscape. |
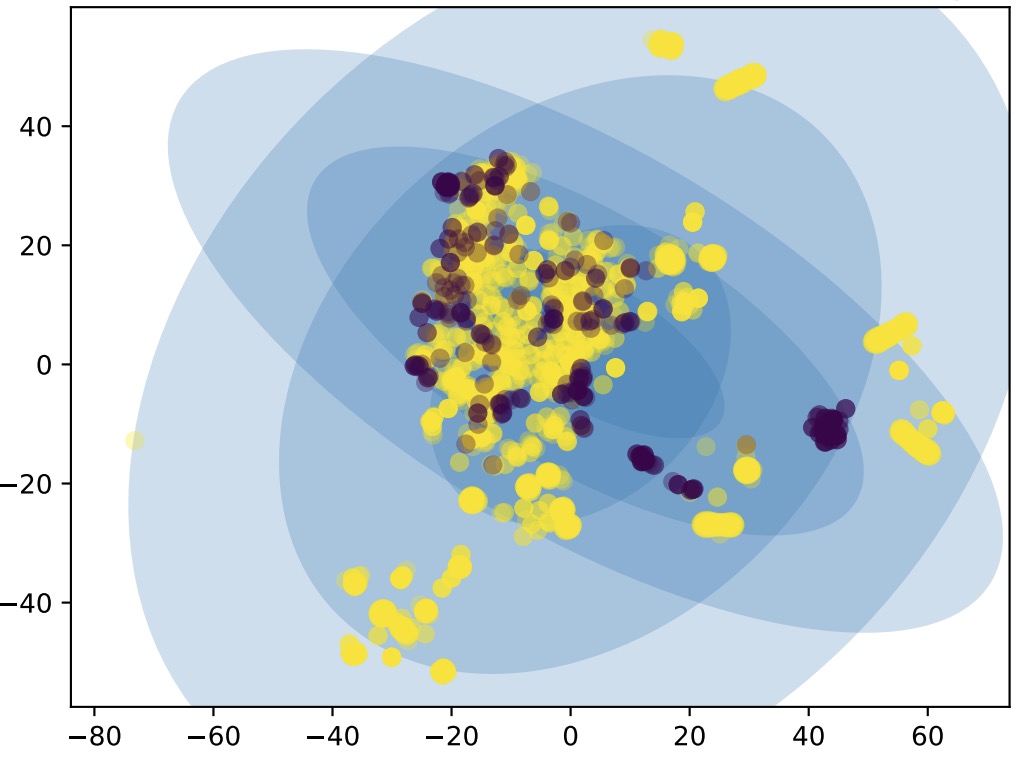 |
Xueqi Yang, Jianfeng Chen, Rahul Yedida, Zhe Yu, Tim Menzies, Empirical Software Engineering Static code warning tools often generate warnings that programmers ignore. Such tools can be made more useful via data mining algorithms that select the actionable warnings; i.e. the warnings that are usually not ignored. In this paper, we look for actionable warnings within a sample of 5,675 actionable warnings seen in 31,058 static code warnings from FindBugs. We find that data mining algorithms can find actionable warnings with remarkable ease. We implement deep neural networks in Keras and PyTorch with static defect artifacts to predict real defects to act on. Utilize regularisers to avoid DNN models from overfitting and lower the runnning overhead. Use Box-counting methods to explore the intrinsic dimension of SE data and match the complexity of machine learning algorithms with the datasets it handles. |
 |
Xueqi Yang, Zhe Yu, Junjie Wang, Tim Menzies, Expert Systems with Applications Static code analysis is a widely-used method for detecting bugs and security vulnerabilities in software systems. As software becomes more complex, analysis tools also report lists of increasingly complex warnings that developers need to address on a daily basis. Such static code analysis tools are usually over-cautious; i.e. they often offer many warnings about spurious issues. In this paper, we identify actionable static warnings of nine Java projects generated by FindBugs with incrementally active learning and machine learning algorithms to achieve higher recall with lower cost by reducing false alarm. And utilize different sampling approaches (random sampling, uncertainty sampling and certainty sampling) to query warnings suggested by active learning algorithm. Interact the system with human oracle to update the system. |
 |
Amritanshu Agrawal, Xueqi Yang, Rishabh Agrawal, Xipeng Shen and Tim Menzies, IEEE Transactions on Software Engineering How can we make software analytics simpler and faster One method is to match the complexity of analysis to the intrinsic complexity of the data being explored. For example, hyperparameter optimizers find the control settings for data miners that improve the predictions generated via software analytics. Sometimes, very fast hyperparameter optimization can be achieved by DODGE-ing; i.e. simply steering way from settings that lead to similar conclusions. But when is it wise to use that simple approach and when must we use more complex (and much slower) optimizers To answer this, we applied hyperparameter optimization to 120 SE data sets that explored bad smell detection, predicting Github issue close time, bug report analysis, defect prediction, and dozens of other non-SE problems. We find that the simple DODGE works best for data sets with low intrinsic dimensionality (around 3) and very poorly for higher-dimensional data (around 8). Nearly all the SE data seen here was intrinsically low-dimensional, indicating that DODGE is applicable for many SE analytics tasks. |
 |
Rahul Yedida, Hong Jin Kang, Huy Tu, Xueqi Yang, Tim Menzies, IEEE Transactions on Software Engineering Automatically generated static code warnings suffer from a large number of false alarms. Hence, developers only take action on a small percent of those warnings. To better predict which static code warnings should not be ignored, we suggest that analysts need to look deeper into their algorithms to find choices that better improve the particulars of their specific problem. Specifically, we show here that effective predictors of such warnings can be created by methods that locally adjust the decision boundary (between actionable warnings and others). These methods yield a new high water-mark for recognizing actionable static code warnings. For eight open-source Java projects (cassandra, jmeter, commons, lucene-solr, maven, ant, tomcat, derby) we achieve perfect test results on 4/8 datasets and, overall, a median AUC (area under the true negatives, true positives curve) of 92%. |
|
|
 |
(1) Utilize Mask R-CNN with PyTorch for satellite images change detection and localization. Assess building damage from satellite imagery with a variety of disaster events and different damage extents. (2) Implement SmartWeather App in C# with Xamarin and Visual Studio. Use Architecture Diagram, Context Diagram and Quality Attribute Scenarios in software design. Utilize Fuzzy logic controller to converts a crisp input value into a fuzzy set with a predetermined lower and upper bound of impreciseness. And follow the Scrum process to iterate and manage software development. (3) Implement word2vec (CBOW and Skip-grams) and doc2vec (Doc2vec and Part-of-speech tagging) models in Python 3 on Sentimental Analysis Dataset and Question Answering Dataset. And compare performance of proposed methods with baseline methods (TF-IDF and BOW) in individual projects. |
|
(1) Credit Scoring via Fuzzy 2-norm Non-kernel Support Vector Machine. Finished an algorithm implementation of linear SVM, SVM with kernels, QSVM and clustered SVM with MATLAB based on the UCI data sets. (2) Quadratic Surface Support Vector Regression for Electric Load Forecasting. Implemented LS-SVR and QSSVR models with the interior point algorithm in the module "quadprog" of MATLAB, and the OLS regression and ANN models with the module "robustfit" and neural network toolbox of MATLAB, respectively. |
 |
(1) Regional Water Supply Stress Index Analysis before and after Intervention, an analysis to regional water problem in Interdisciplinary Contest in Modeling in 2016. (2)Allocation of taxi resource in the Internet era, the entry of China Undergraduate Mathematical Contest in Modeling in 2015. I partook problem analysis, data preprocessing, model construction, algorithm implementation and optimization. |
|
|
 |
Efficient Deep Learning - Fall 2022 (NCSU)
Artificial Intelligence 2 - Spring 2021 (NCSU)
Natural Language Processing, Computational Applied Logic - Fall 2020 (NCSU)
Spatial and Temporal Data Mining, Software Engineering - Spring 2020 (NCSU)
Design and Analysis of Algorithms,Computer Networks - Spring 2019 (NCSU)
Foundations of Software Science, Artificial Intelligence - Fall 2018 (NCSU)
C, Java, Data Ming, Data Structure, JavaScript, Matlab, SQL, Statistics and Operation Research- Undergraduate
|
|
|
 |
|
|
|
 |
|
|
|